
Measuring the user experience and digital performance implies to be interested in measurement scales. The choice of the graduation of the tool with which a measurement is carried out will have an impact on the way in which the data collected can be represented and processed. This is why it is necessary to carefully choose the measurement scales that will be used to characterize a digital service or its users. Indeed, not all of these scales have the same advantages and disadvantages.
Four types of scales
The notion of measurement scale is closely linked to that of variable. A variable is a quantity that can take different values (or modalities). A variable can take at least two values (minimum condition of its variation, it is then called dichotomous or binomial), but it can take several values (multinomial), or even an infinity of values (it is called continuous). There are two types of variables: qualitative and quantitative. Qualitative variables are evaluated using a label (a wordl). Quantitative variables are represented by numbers.
There are four types of measurement scales, from the simplest to the most elaborate:
- nominal (qualitative),
- ordinal (qualitative),
- interval (quantitative),
- ratio (quantitative).
Each measurement scale has its own characteristics, but retains the properties of the lower level scales (but the reverse is not true). However, it is possible to transform one scale into another, in one direction or the other, as we will see below.
Each measurement scale is characterized by its measure of central tendency index and its dispersion. The central tendency corresponds to the typical value of the measured variable (e. g. artihmetic mean). Conversely, the dispersion represents the variability or range of the measurement (e. g. standard deviation). We present below a simplified version of the synthesis proposed by Yvonnick Noël in his book :
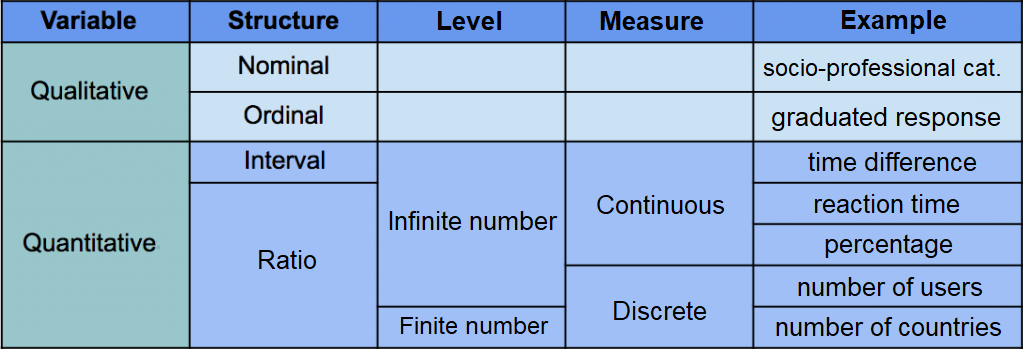
Summary table of measurement scales (according to Yvonnick Noël)
Qualitative variables
Nominal scale
The term scale is not really appropriate for nominal scales according to David C. Howell. Indeed, they do not classify the observations. They are limited to designating them by a label (man – woman, employee – self-employed – unemployed). This label can be a name or a number (in this case, it does not contain any mathematical values, for example group 1, group 2 or group 3).
It is only possible to count the number of elements (number) in each of the categories or classes. If this number is related to the total number of observations in all categories, then we speak of frequency (which can be expressed as a percentage, for instance).
The central tendency index of the nominal scale is the mode. This is the category with the highest number of observations. It is therefore the value with the highest frequency. Thus, within a set of measures (called a distribution, in statistical jargon) there may be no mode (equal distribution of enrolment in each class), or several modes. This type of measurement scale only makes it possible to classify the object of the measurement in one category or another.
The nominal scale does not allow to calculate a dispersion index.
Ordinal scale
In addition to classifying observations into categories (such as nominal scales), ordinal scales classify these categories in relation to each other in a defined order. This is why they constitute real “scales”. They therefore assign a rank to the different categories. Likert scales, commonly used in survey responses, are very good examples of ordinal scales :
- Strongly agree
- Agree
- Neither one nor the other
- Disagree
- Strongly disagree
Ordinal scales do not measure the size of the gap between these ranks. We cannot therefore consider that there is the same gap between “strongly agree” and “agree” as between “neither” and “disagree”, even if these ordered categories are represented here by numbers. Only the order matters. This is why it is not possible to calculate a sum or an average on such data, because this would have no mathematical meaning.
The central tendency of an ordinal scale can be represented by the mode, but also by the median. The median is the value that divides an ordered series of observations into 2 equal parts (i.e. each containing the same number of observations).
Unlike nominal scales, ordinal scales make it possible to calculate a dispersion index, and thus to assess the variability of the distribution of results. It is called the quantile, i.e. the value that divides a set of measurements into intervals containing the same number of data. The median is therefore the quantile that separates the data set into two groups of equal size.
Quantitative variables
Interval scales
Interval scales are used to assess the difference between the modalities of the scale. For example, there is the same difference between the year 1935 and 1940 as between 2007 and 2012. However, this type of scale does not have a “natural” zero. Year 0 does not mean that there is no year. It is an arbitrary convention. Therefore, we cannot say that the year 2000 is twice as recent as the year 1000.
Ratio scale
Conversely, the ratio scales have a meaningful zero. In this case, the zero is not arbitrary and really means an absence of the measured phenomenon. This is the case for duration measurements: a time of zero seconds means that no time has passed. Thus, 40 seconds are twice as long as 20 seconds. It is these reporting scales that offer the most possibilities in terms of statistical data processing.
Interval and reporting scales can be discrete or continuous.
If the scale is discrete, the interval between two values of the scale cannot be less than one. The number of sessions using a digital service is discrete: there are no half-sessions. However, the average number of sessions can be calculated, even if the value obtained does not correspond to an integer.
If the scale is continuous, then the measurement can potentially take an infinite number of values. This is the case for elapsed time measurements. It is always theoretically possible to specify the measurement at a higher level (e.g. tenth of a second, hundredth seconds, etc.), even if the measurement tool does not allow it in practice.
For measures of variability and central tendency, quantitative scales (whether interval or ratio) allow to calculate the mean and the standard deviation. Since they retain the properties of the lower level scales, they also make it possible to determine their median and quantiles.
For the mode, it is more complicated. Indeed, if a variable can take an infinite number of values (as it is the case for continuous variables), the mode has little interest, since each measurement can be different from all the others (if the measurement tool is sufficiently accurate). In this case, it is preferable to use the notion of modal class, which corresponds to a grouping of values within intervals. Of course, the choice of the width of the interval remains arbitrary, but if we want to be able to evoke the notion of modal class (i.e. the one containing the most observations), the classes must be of an equal range.
Switch from one scale to another
Despite their apparent compartmentalization, it is possible to switch from one scale to another. For example, the type of terminal used to view a site is a nominal variable (smartphone, tablet or computer). However, if we consider the screen size of these devices, we can make them an ordinal variable, from the smallest to the largest. Similarly, devices could be classified according to their screen resolution, which is a ratio variable. But it is possible to do the opposite: we can choose to fragment these resolutions into arbitrarily chosen classes (e. g. from 0 to 200,000, from 200,001 to 400,000, and so on, keeping a constant interval).
These choices must be guided by a requirement for rigour and intellectual honesty in order to achieve the objectives we have set for ourselves.