
Avoir l’ambition de mesurer l’expérience utilisateur et la performance digitale implique de s’intéresser aux échelles de mesures. En effet, le choix de la graduation de l’outil avec lequel on va réaliser une mesure va avoir un impact sur la façon dont on pourra représenter et traiter les données que l’on recueille. C’est pour cela qu’il faut soigneusement choisir les échelles de mesure que l’on va utiliser pour caractériser un service digital ou ses utilisateurs, car toutes n’ont pas les mêmes avantages et inconvénients.
Quatre types d’échelles
La notion d’échelle de mesure est intimement liée à celle de variable. Une variable est une grandeur qui peut prendre différentes valeurs (ou modalités). Une variable peut prendre au minimum deux valeurs (condition minimale de sa variation, elle est alors dite dichotomique ou binomiale), mais elle peut prendre plusieurs valeurs (multinomiale), voire même une infinité de valeurs (on dit alors qu’elle est continue). On distingue deux types de variables : qualitatives et quantitatives. Les variables qualitatives sont évaluées grâce à un libellé (un mot, une étiquette). Les variables quantitatives sont quant à elles représentées par des nombres.
Il existe quatre types d’échelles de mesure, de la plus simple à la plus élaborée :
- nominales (qualitatives),
- ordinales (qualitatives),
- d’intervalle (quantitatives),
- de rapport (quantitatives).
Chaque échelle de mesure dispose de caractéristiques qui lui sont propres, mais conserve les propriétés des échelles de niveau inférieur (mais la réciproque n’est pas vraie). Toutefois, il est possible de transformer une échelle en une autre, dans un sens ou dans l’autre, comme nous le verrons plus bas.
Chaque échelle de mesure se caractérise par son indice de tendance centrale et sa dispersion. L’indice de tendance centrale correspond à la valeur typique de la variable mesurée (ex: la moyenne). A l’inverse, l’indice de dispersion va représenter la variabilité ou l’étendue de la mesure (ex: l’écart-type). Nous présentons ci-dessous une version simplifiée de la synthèse proposée par Yvonnick Noël dans son ouvrage :
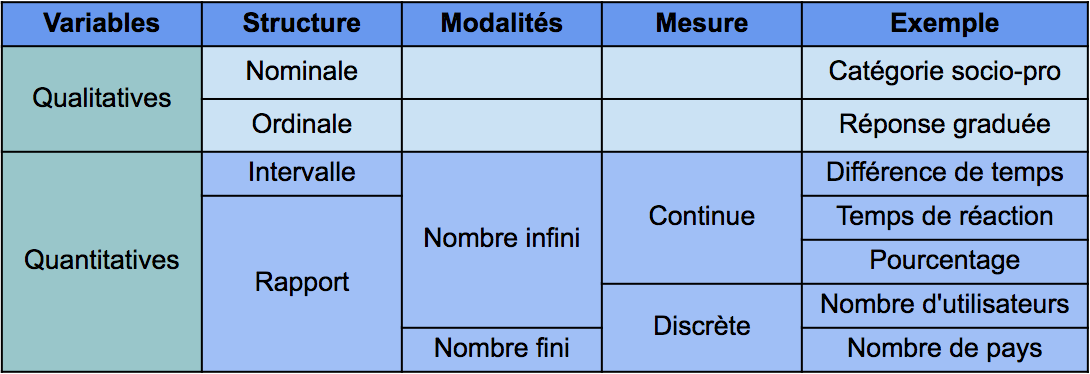
Tableau synthétique des échelles de mesures (selon Yvonnick Noël)
Variables qualitatives
Les échelles nominales
Le terme d’échelle ne convient pas vraiment aux échelles nominales selon David C. Howell. En effet, elles ne classent pas les observations. Elles se limitent à les désigner par une étiquette (homme – femme, salarié – indépendant – sans emploi). Cette étiquette peut être un nom ou un chiffre (dans ce cas, il ne véhicule aucune grandeur mathématique, par exemple groupe 1, groupe 2 ou groupe 3).
Il est seulement possible de compter le nombre d’éléments (effectif) dans chacune des catégories ou classes. Si cet effectif est rapporté au nombre total d’observations toutes catégories confondues, on parle alors de fréquence (que l’on pourra exprimer en pourcentage, par exemple).
L’indice de tendance centrale de l’échelle nominale est le mode. C’est la catégorie sur laquelle se retrouve le plus grand nombre d’observations. C’est donc la valeur qui présente la fréquence la plus élevée. Ainsi, au sein d’un ensemble de mesures (que l’on appelle une distribution, dans le jargon statistique) il peut ne pas y avoir de mode (répartition égale de l’effectif dans chaque classe), ou bien plusieurs modes. Ce type d’échelle de mesure ne permet que de classer l’objet de la mesure dans telle ou telle catégorie.
L’échelle nominale ne permet pas de calculer d’indice de dispersion.
Les échelles ordinales
En plus de ranger les observations dans des catégories (comme les échelles nominales), les échelles ordinales classent ces catégories les unes par rapport aux autres selon un ordre défini. C’est en cela qu’elles constituent de véritables « échelles ». Elles attribuent donc un rang aux différentes catégories. Les échelles de Likert, couramment utilisées dans les réponses aux enquêtes sont de très bons exemples d’échelles ordinales :
- Tout à fait d’accord
- D’accord
- Ni l’un ni l’autre
- Pas d’accord
- Pas du tout d’accord
Les échelles ordinales ne permettent pas de mesurer la taille de l’écart qui existe entre ces rangs. On ne peut donc pas considérer qu’il existe le même écart entre « tout à fait d’accord » et « d’accord » qu’entre « ni l’un ni l’autre » et « pas d’accord », même si ces catégories ordonnées sont représentées ici par des chiffres. Seul compte l’ordre. C’est pourquoi on ne peut pas réaliser sur de telles données le calcul d’une somme ou d’une moyenne, car cela n’aurait aucun sens mathématique.
On peut représenter la tendance centrale d’une échelle ordinale par le mode, mais également par la médiane. La médiane est la valeur qui partage une série d’observation ordonnée en 2 parties égales (c’est-à-dire contenant chacune le même nombre d’observations).
Contrairement aux échelles nominales, les échelles ordinales permettent de calculer un indice de dispersion, et donc d’évaluer la variabilité de la distribution des résultats. On le nomme le quantile, c’est-à-dire la valeur qui divise un ensemble de mesures en intervalles contentant le même nombre de données. La médiane est donc le quantile qui sépare le jeu de données en deux groupes de tailles égales.
Variables quantitatives
Les échelles d’intervalles
Les échelles d’intervalles permettent d’évaluer la différence qui existe entre les modalités de l’échelle. Par exemple, il existe la même différence entre l’année 1935 et l’année 1940, qu’entre 2007 et 2012. Par contre, ce type d’échelle ne présente pas un zéro « naturel ». L’année 0 ne signifie pas une absence d’année. C’est une convention arbitraire. Par conséquent, on ne peut pas dire que l’an 2000 est deux fois plus récent que l’an mille.
Les échelles de rapport
A l’inverse, les échelles de rapport disposent d’un zéro naturel. Dans ce cas, le zéro n’est pas arbitraire et signifie véritablement une absence du phénomène mesuré. C’est le cas des mesures de durée : un temps de zéro seconde signifie une absence de temps passé. Ainsi, 40 secondes sont bien le double de 20 secondes. Ce sont ces échelles de rapport qui offrent le plus de possibilités en termes de traitement statistique des données.
Les échelles d’intervalles et de rapport peuvent être discrètes ou continues.
Si l’échelle est discrète, l’intervalle entre deux valeurs de la graduation ne peut être inférieur à l’unité. Le nombre de sessions d’utilisation d’un service digital est discret : il n’existe pas de demi-sessions. Pour autant, on peut calculer le nombre moyen de sessions, même si la valeur obtenue ne correspond pas à un nombre entier.
Si l’échelle est continue, alors la mesure peut potentiellement prendre une infinité de valeurs. C’est le cas des mesures de temps passés. Il est toujours possible théoriquement de préciser la mesure à un niveau supérieur (ex: 10 ème de seconde, 100 ème de seconde, etc.), même si l’outil de mesure ne le permet pas dans la pratique.
Concernant les mesures de variabilité et de tendance centrale, les échelles quantitatives (qu’elles soient d’intervalles ou de rapport) permettent de calculer une moyenne et un écart-type. Puisqu’elles conservent les propriétés des échelles de niveaux inférieurs, elles permettent aussi d’en déterminer la médiane et les quantiles.
Pour le mode, les choses sont plus compliquées. En effet, si une variable peut prendre une infinité de valeur (comme c’est le cas pour les variables continues), le mode n’a que peu d’intérêt, puisque chaque mesure peut être différente de toutes les autres (si l’outil de mesure est suffisamment précis). Dans ce cas, on préfèrera utiliser la notion de classe modale, qui correspond à un regroupement de valeurs au sein d’intervalles. Bien évidemment, le choix de la largeur de l’intervalle reste arbitraire, mais si l’on veut pouvoir évoquer la notion de classe modale (c’est-à-dire celle qui contient le plus d’observations), il faut que les classes soient d’une étendue équivalente.
Passer d’une échelle à l’autre
En dépit de leur cloisonnement apparent, il est possible de passer d’une échelle à l’autre. Par exemple, le type de terminal utilisé pour consulter un site est une variable nominale (smartphone, tablette ou ordinateur). Cependant, si l’on s’attache à considérer la taille de l’écran de ces appareils, on peut en faire une variable ordinale, du plus petit au plus grand. De la même façon, on pourrait classer les appareils en fonction de la résolution de leur écran, qui est une variable de rapport. Mais il est possible de faire le chemin inverse : on peut choisir de fragmenter ces résolutions selon des classes arbitrairement choisies (ex : de 0 à 200 000, de 200 001 à 400 000, et ainsi de suite, en conservant un intervalle constant).
Ces choix doivent être guidés par une exigence de rigueur et d’honnêteté intellectuelle au service des objectifs que l’on s’est fixés.